MINT handles metadata records from the content provider's delivery up to the aggregation repository(-ies), publication mechanism(s) and front-end(s). It makes data interoperable through the use of well-defined metadata models and the alignment of the providers' records with certain requirements and schemata. MINT uses a visual mapping editor for the XSL language to implement crosswalks to the reference metadata model. It is being used by a growing number of providers that align proprietary data structures to a variety of standard or aggregation- specific models and in that way establish and maintain interoperability with other providers and Europeana.
Ingest
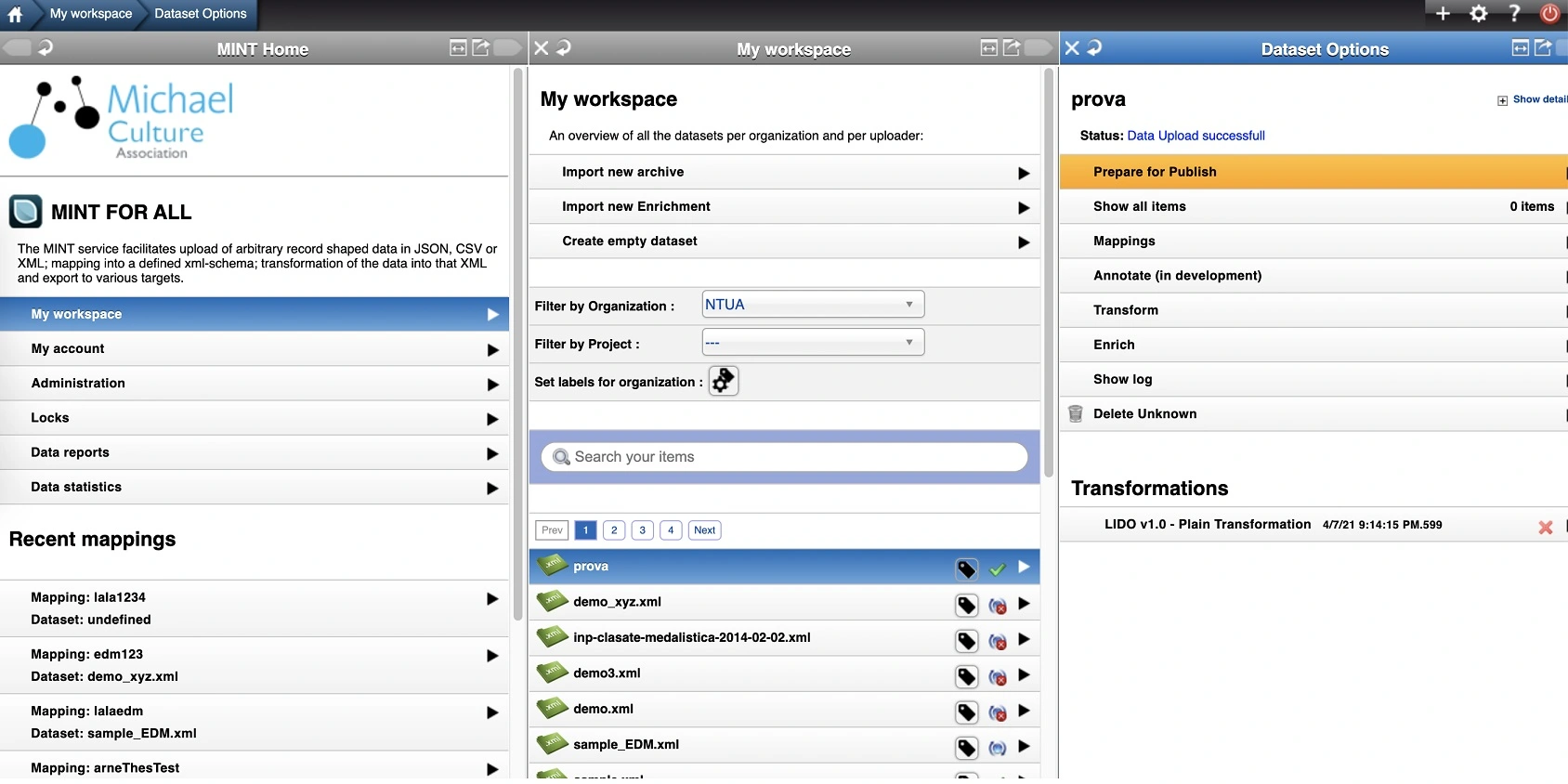
Registered users can upload their metadata records in JSOM, OWL/RDF, XML or CSV serialization, using the HTTP, FTP and OAI-PMH protocols. Users can also directly upload and validate records in a range of supported metadata standards (XSD). XML records are stored and indexed for statistics, previews, access from the mapping tool and subsequent services.
Processing
Handling of metadata records includes indexing, retrieval, update and transformation of XML files and records. XML processors are used for validation and transformation tasks as well as for visualisation purposes. For issues of scalability with respect to the amount of data and concurrent heavy processing tasks, parts of the services are multi-threaded and queue processing mechanisms are implemented.
Align & Normalize
MINT offers a visual mapping editor that enables users to map their dataset records to a desired XML target schema. Mapping is performed through drag-and- drop and input operations which are translated to the corresponding code. The editor visualizes the input and target XSDs, providing access and navigation of the structure and data of the input schema, and the structure, documentation and restrictions of the target one. It supports string manipulation functions for input elements in order to perform 1-n and m-1 (with the option between concatenation and element repetition) mappings between the two models. Additionally, structural element mappings are supported, as well as constant or controlled value (target schema enumerations) assignment, conditional mappings (with a complex condition editor) and value mappings between input and target value lists. Mappings can be applied to ingested records, edited, downloaded and shared as templates.
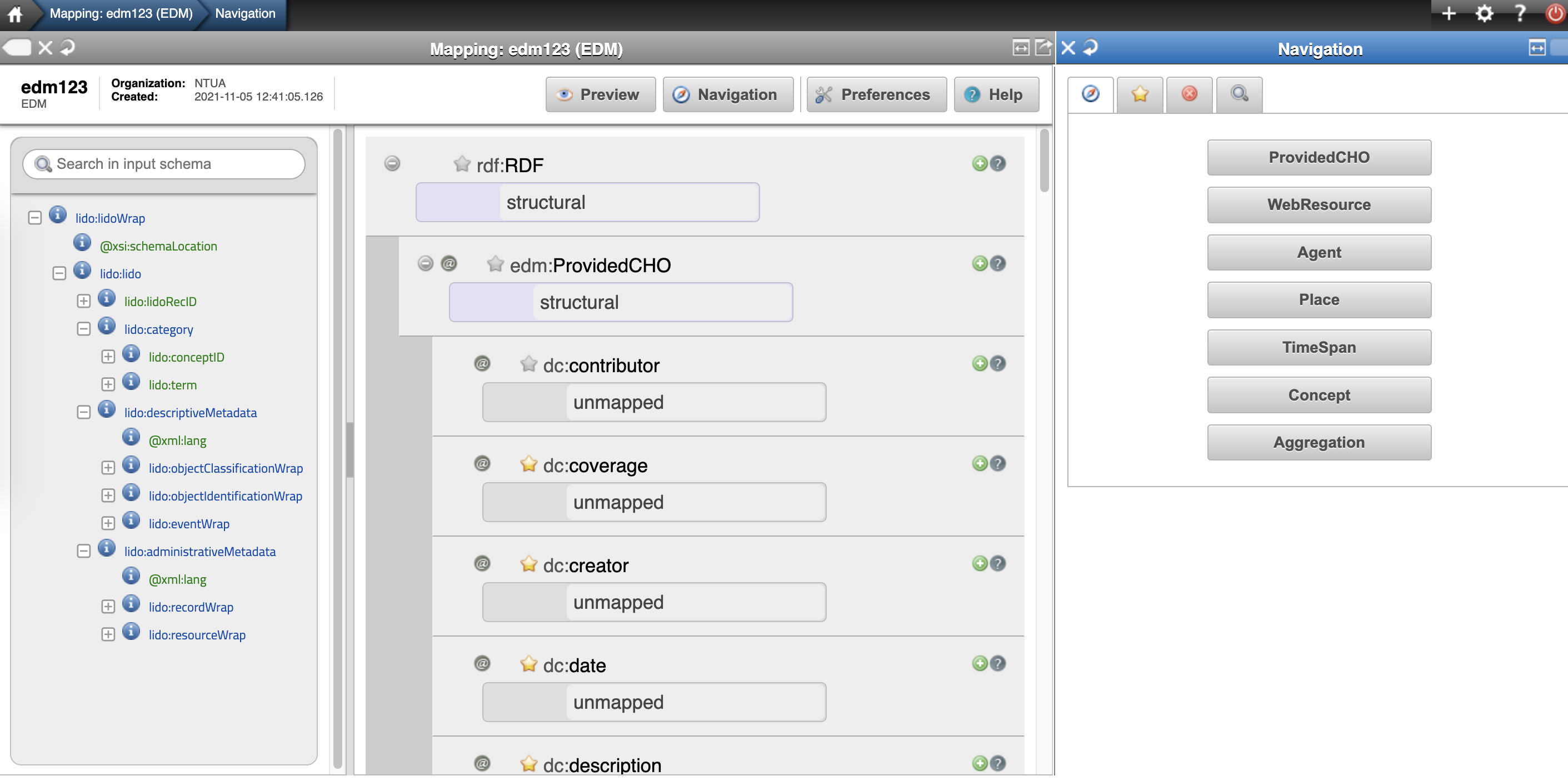
Preview interfaces present the steps of the aggregation such as the current input xml record, the XSLT code of mappings, the transformed record in the target schema, subsequent transformations from the target schema to other models of interest (e.g. Europeana's metadata schema), and available html renderings of each xml record. Users can transform their selected collections using complete and validated mappings in order to publish them in available target schemas for the required aggregation and remediation steps.
Various additional resources such as terminologies, vocabularies, authority files and dictionaries are used to reinforce an aggregation's homogeneity and interoperability with external data sources. A typical usage scenario is the connection of a local (server) or online resource with a metadata element in order to be used during mapping/normalization. These resources can be XML, RDF/OWL, SKOS or even proprietary systems accessed through APIs.
Normalization services such as group editing and value mapping are currently being implemented as standalone tasks for direct imports
Remediate
MINT is being used to publish metadata in XML, JSON or RDFS/OWL according to the mechanism and usage. Typical scenarios include an OAI-PMH repository for XML records, SPARQL endpoints for triple stores, Lucene-based indexes for search engines and RESTful APIs for third party services.



